• 4 minutes read
Why Your Offboarding Process Is Broken (And Why RAG Won't Fix It)

If you run a technical team, you already know the math. Twenty percent of your engineers hold eighty percent of the critical context. They are the ones who know why the legacy billing service was built with that weird edge case, how to placate the temperamental CI/CD pipeline, and which undocumented API endpoints are actually load-bearing.
When one of these key players hands in their notice, the standard playbook kicks in. You schedule transition meetings. You ask them to write documentation. You might even record a few Zoom sessions where they walk through the architecture.
And yet, three months later, when the system goes down at 2 AM, none of that preparation helps. The on-call engineer is still digging through old Slack threads, trying to reverse-engineer the original author's thought process.
The asymmetry of knowledge transfer is one of the most frustrating problems in engineering leadership. We treat offboarding as a data storage problem when it is actually a context preservation problem. Let's break down the four most common myths about how we handle departing knowledge, and why our standard solutions consistently fail.
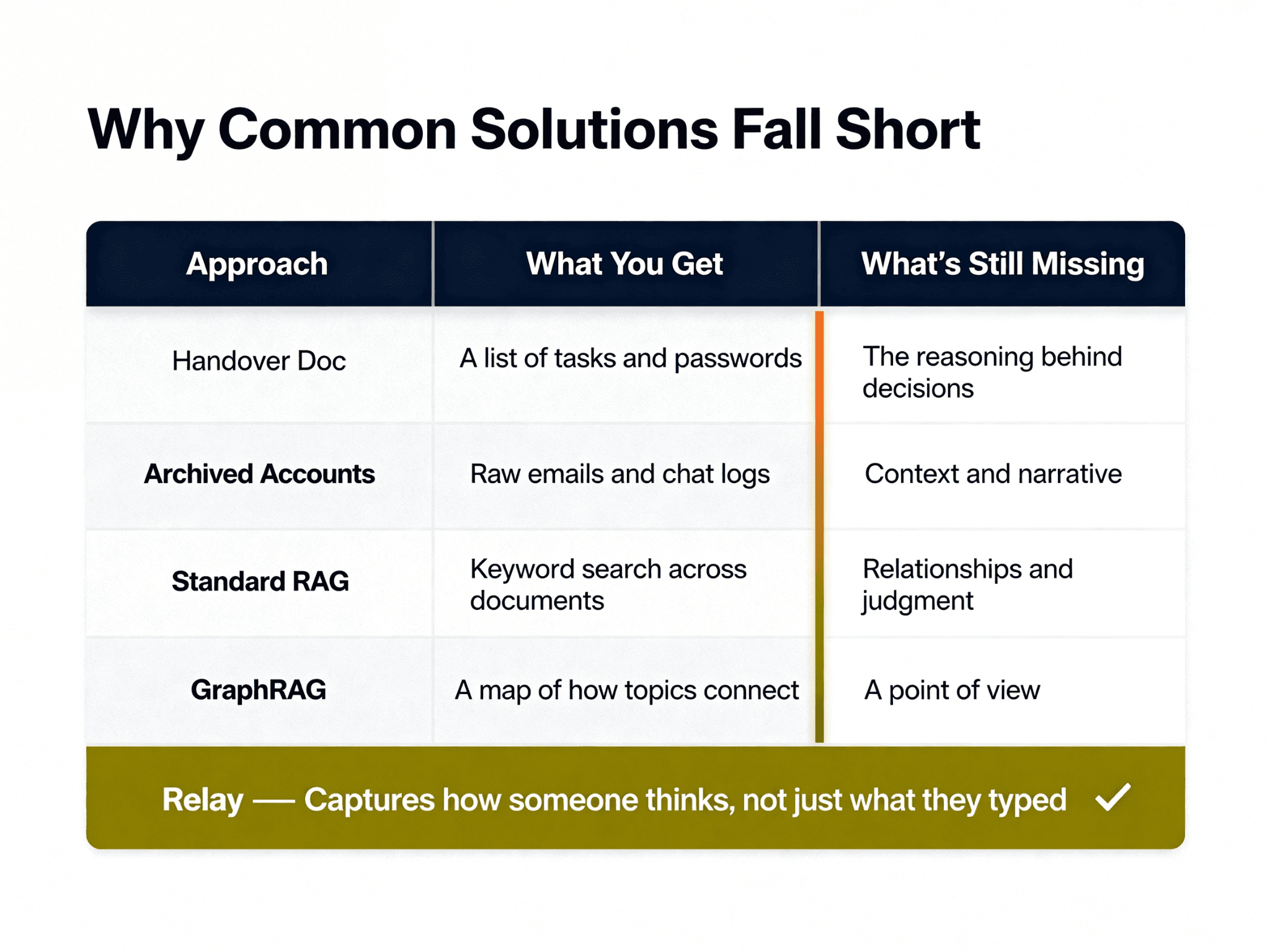
Myth vs Reality: The Four Failed Solutions
Solution 1: The Comprehensive Handover Document
The Myth: If we just give the departing engineer two weeks to write down everything they know, we'll have a permanent record of their expertise.
The Reality: Handover documents are almost entirely useless in a crisis. They are written in a vacuum, attempting to predict future problems without knowing the future context. Gartner found that less than 20% of enterprise knowledge management initiatives deliver expected value — primarily because they capture structured data while leaving tacit knowledge untouched.
Furthermore, static documentation decays rapidly. The average enterprise wiki has a half-life of about 18 months before it becomes too outdated to be reliably useful. In a fast-moving startup, that half-life is closer to three months. When an engineer writes a handover doc, they are writing a snapshot of a system that is already changing. They document the "what" and the "how," but rarely the "why." And the "why" is exactly what you need when things break.
Solution 2: The "Record Everything" Approach
The Myth: We'll just record hours of screen-sharing sessions where the departing engineer explains the codebase.
The Reality: Video is a terrible medium for searching and retrieving technical context. If an engineer needs to know why a specific database migration was structured a certain way, they cannot afford to scrub through four hours of unindexed Zoom recordings hoping to find the five-minute segment where it was mentioned.
These recordings usually end up sitting in a shared drive, unwatched, serving only as a psychological safety blanket for management. They provide the illusion of knowledge transfer without any of the utility.
Solution 3: Standard RAG (Retrieval-Augmented Generation)
The Myth: We'll just dump all their emails, Slack messages, and Jira tickets into a vector database and put a standard RAG chatbot on top of it.
The Reality: Standard RAG is excellent at retrieving facts ("What is the IP address of the staging server?"). It is terrible at synthesizing judgment ("Why did we choose this architecture over the alternative?").
When you ask a standard RAG system a complex question, it retrieves the top-k most semantically similar chunks of text. But technical context is rarely contained in a single chunk. It is distributed across a Slack thread from Tuesday, a pull request comment from Thursday, and a design doc from three months ago. Standard RAG lacks the ability to connect these disparate pieces of information into a coherent narrative of intent. It gives you fragments, not understanding.
Solution 4: GraphRAG and Advanced Architectures
The Myth: If standard RAG isn't enough, we'll build a complex GraphRAG system to map the relationships between all the entities in our codebase and communications.
The Reality: While GraphRAG is a significant step up in capability, it is still fundamentally a search engine. It can tell you that Entity A is connected to Entity B, but it struggles to emulate the persona and reasoning style of the departing engineer.
When a junior developer asks a question, they don't just need a list of related documents. They need a synthesized answer that takes into account the specific constraints and historical context of the project—the kind of answer the departing engineer would have given. GraphRAG maps the data, but it doesn't map the mind.
Why Now? The Technical Unlock
This wasn't solvable two years ago. The models weren't good enough to synthesize reasoning from unstructured conversational data. What's changed is that frontier LLMs can now do something qualitatively different: they can infer intent and judgment from the pattern of how someone communicates, not just what they said. That's the technical unlock that makes Relay possible now, and not before.
We are no longer limited to keyword matching or simple semantic similarity. We can now process the vast, messy reality of human communication—the half-finished thoughts in Slack, the detailed arguments in pull requests, the quick clarifications in email—and extract the underlying mental models.
But there's a second unlock that matters just as much, and it's one we're uniquely positioned to leverage. Relay is built on EverMemOS, the long-term memory operating system developed by our sister team at Evermind.ai — part of the same Shanda Group family. EverMemOS isn't a memory database. It's a memory processor. The distinction is critical.
Traditional memory systems — including most RAG implementations — are built around retrieval: you ask a question, the system finds the most relevant chunks of text, and returns them. EverMemOS goes further. Inspired by the human brain's memory architecture (from hippocampal indexing to cortical long-term storage), it extracts continuous semantic blocks into structured episodic memory units, then actively uses those memories to influence reasoning in real time — not just surface them as search results.
The results speak for themselves: EverMemOS currently achieves 92.3% accuracy on the LoCoMo benchmark and 82% on LongMemEval-S, both surpassing the previous state-of-the-art. It is the first memory system capable of simultaneously supporting both one-on-one dialogue and complex multi-party collaboration — which is exactly the environment a lean startup operates in.
This is the infrastructure layer that makes Relay's Digital Twin genuinely different from a sophisticated search engine. The memory doesn't just sit there waiting to be queried. It participates.
The Real Gap: Database vs Colleague
The fundamental flaw in all traditional offboarding solutions is that they treat knowledge as a static asset to be queried. They build databases.
But when your team is trying to solve a hard problem, they don't want to query a database. They want to talk to a colleague. They want to bounce ideas off someone who understands the historical context. They want to say, "I'm thinking of refactoring the auth module this way, what am I missing?"
A database cannot answer that question. A database cannot say, "We tried something similar last year, and it caused a race condition in the user provisioning flow."
This is the gap that Relay fills. By ingesting the departing employee's digital footprint—their code, their communications, their documentation—Relay creates an interactive AI Digital Twin. It doesn't just retrieve information; it synthesizes it using the specific reasoning patterns of that individual. It turns static archives into an active, conversational participant in your team's workflow.
The Hidden Cost of "We Can Build This"
As technical founders, our first instinct is often to build rather than buy. You might look at the concept of an AI Digital Twin and think, "We have an OpenAI API key and a vector database. We can hack this together over a weekend."
You can certainly build a basic RAG prototype over a weekend. But building a production-grade context-aware RAG system from scratch typically requires months of engineering time and ongoing maintenance.
The challenge isn't the basic retrieval; it's the edge cases. It's handling the permissions and access controls so the AI doesn't leak sensitive HR conversations. It's building the ingestion pipelines that can handle the messy, unstructured reality of Slack exports and Google Drive folders. It's tuning the prompts and the retrieval strategies so the AI actually sounds and reasons like the departing employee, rather than a generic chatbot.
Every week your best engineers spend building and maintaining an internal knowledge retrieval tool is a week they aren't spending on your core product. The opportunity cost is massive.
Preserving the Person, Not Just the Data
When a key team member leaves, you aren't just losing data. You are losing judgment. You are losing the hard-won intuition about what works and what doesn't in your specific technical environment.
Traditional offboarding tries to capture the data and accepts the loss of the judgment. It's a compromise we've accepted because, until recently, we had no other choice.
Relay changes that equation. It allows you to preserve the person's expertise in a format that remains accessible, interactive, and useful long after their final day. It transforms offboarding from a frantic attempt to write everything down into a seamless transition of capability.
Stop asking your departing engineers to write documents that no one will read. Stop building internal search engines that no one will use.
Capture their context. Preserve their judgment. Keep your team moving forward.
Ready to see how Relay can preserve your team's critical context?

